What Building Enterprise AI Taught Us About Why Agents Fail




This piece is a reflection on what building enterprise AI taught us about production. The patterns behind agent failures, the infrastructure they exposed, and why capability alone was never enough.
You'll learn:
Why execution is where most agents fail
How context should be layered for production
Why evaluation, governance, and observability create trust
Why the harness is ultimately the product
Every major technology wave has two chapters. The first is about the capability. The second is about the infrastructure that makes that capability reliable enough to actually use.
We are deep into the first chapter of the agent era. Teams are executing multi-step workflows with a fluency that would have seemed implausible three years ago. Hundreds of teams have shipped agents into production. Venture capital has poured in. The demos are genuinely impressive.
And yet the failure rates in production remain stubbornly high. Because the industry is still treating agents as a capability problem when what they actually need is an infrastructure problem solved.
The teams that have been building in enterprise AI long enough have quietly moved past the question of capability. They are working on something harder and less glamorous: the harness around the agent. The governance layer. The testing infrastructure. The observability that lets you explain what your agent did and why when an enterprise customer asks. This is the work that determines whether an agent survives contact with the real world.
We learned this the hard way, across dozens of production incidents where everything performed exactly as expected and the system still failed. The structure around it wasn't there. That gap, between a capable agent and a trustworthy one, is what we have spent the last few years building toward.
The Problem Was Never the Brain

When an agent handles a complex enterprise workflow, it isn't doing one thing. It is doing ten or fifteen things in sequence, each depending on the one before it, each producing context that shapes what should come next. That is where most agents actually break. In the execution structure, not the reasoning.
We started calling this the OCD framework, because it captures three distinct failure patterns we kept seeing in the wild.
Order of Execution. Enterprise workflows are rarely a clean list of steps you run top to bottom. They have hidden dependencies. Step three might need data that only becomes available after step six runs. An agent that doesn't recognize this will barrel through in the wrong order, hit a dead end, and either stall completely or keep going on whatever incomplete foundation it has. That is a sequencing failure, and it is remarkably common even in workflows that look simple on paper.
Contextual Execution. A plan that makes sense at the start of a run can become completely wrong three steps in. Every action produces new information, and that information should change what happens next. A good agent reads what the environment is telling it and adjusts. A brittle agent commits to the original plan no matter what signals it gets along the way. Think of a surgeon who keeps operating after discovering the patient's anatomy is different than the scans suggested. The problem isn't skill. It's rigidity in the face of new information.
Depth of Execution. Knowing what to do and knowing how far to go are two different skills. Some tasks genuinely need twenty steps done carefully. Others need twelve done well. An agent that stops too early leaves the job unfinished in ways that aren't immediately obvious. One that goes too far starts activating downstream processes that weren't supposed to run yet. Neither failure looks dramatic from the outside, which is exactly what makes both of them so easy to miss until real damage is done.
Every production incident we have investigated traces back to at least one of these three patterns. The execution structure was fragile.

Agents Break When Your Product Moves Forward Without Them
Here is something nobody tells you when you ship your first agent into production: the agent you built last month is quietly becoming wrong today.
Products evolve. Features change. Logic shifts in ways that don't always produce a changelog. Agents, left on their own, keep executing against a version of the world that no longer exists.
We found two very different ways this plays out, and they require completely different responses.
The first is when the product visibly changes. A new feature ships, a tool gets modified, a workflow is redesigned. These failures at least leave a paper trail. You can point to what changed, test against the new behavior, and catch breakage before it reaches users. Painful, but navigable.
The second kind is trickier. Nothing new got shipped. No APIs changed. But somewhere under the hood, the way things connect started working a little differently. The product looks the same. The agent's knowledge looks the same. The gap between them, however, has been growing for weeks. You find out when something fails in a way that looks like an error but is really just the world having moved on without the agent noticing.
This is why evaluation harnesses are infrastructure, not a feature you add later. The final output alone cannot tell you whether the agent arrived there correctly. Two completely different paths through a workflow can produce the same answer. One of them was sound. The other was a lucky mistake. You need to watch the path, not just the destination.
The Agent That Works in Europe Breaks in Singapore
Most people imagine agent failures as technical events. A bad prompt. A missed step. What we found in enterprise deployments is that the most expensive failures are organizational. They are governance failures.
We operate across industries and geographies. The same agent can work correctly in one regulatory environment and cause real problems in another. Because the rules and constraints it was operating under were never right for that context to begin with.
You cannot hand an agent a large document full of every possible rule for every possible situation and expect it to always surface the right ones. That is not how context works at scale. What you need is a way to deliver the right knowledge to the right execution at the right time, based on who is running it, where they are, and what is actually permitted for them.
The way we think about this is three distinct context layers.
Global context is the product and process knowledge that applies universally.
Runtime context is added dynamically to each execution based on the client, geography, and the constraints for that run.
Tenant context is the implementation knowledge specific to how a particular client has configured the system.
Each layer serves a different purpose. Without the boundaries between them, agents start bleeding context across accounts and regions. Rules meant for one client quietly get applied to another. Constraints designed for one geography creep into a different one. We have watched this happen in production. It is not theoretical.
The data access problem lives in the same territory. Agents have tool access, and they will use it broadly if nothing stops them. An agent operating with looser permissions than the underlying platform it sits within has effectively created a parallel access path into the system, whether anyone intended that or not. The architectural decision we made early was to not build a separate access control layer for the agent layer at all. The agent inherits the security rules that already exist in the platform and operates entirely within them. If a person cannot perform an action in the platform, the agent working on their behalf cannot either. Security is not something you bolt on afterward. It needs to be a property the system is born with.
A Log Is Not the Same Thing as Understanding
There is a phrase I keep coming back to: if you cannot explain what the agent did and why, you do not have an enterprise product. You have a prototype with an enterprise price tag.
A log that says "executed step seven" tells you almost nothing. Real observability means capturing the reasoning behind each decision. What was the agent looking at when it chose that path? What did it interpret from the step before? Why did it stop where it stopped?
Without this, investigating a failure becomes forensics on an incomplete record. You are sifting through what was captured trying to reconstruct a decision process that was never properly written down. In regulated industries, that is a compliance problem. In any enterprise context, it is a trust problem. And trust lost over a poorly explained agent action is very slow to come back.
Rollouts belong in the same conversation. Flipping from a test environment to full production is not a deployment strategy. It is a gamble. The right approach is gradual: ship to a small slice, watch behavior closely, expand only once you are confident. This is how careful engineering teams have shipped software for decades. The discipline is identical. What has changed is that when an agent acts, it does not just display something on a screen. It does things in the world.
Better Models Don't Create Trust
Things are improving fast and it is tempting to believe that capability gains will eventually wash away the operational problems underneath.
The execution layer, the sequencing, the mid-run adjustments, the depth calibration, those do get better as the underlying capability improves. We have seen it already and it will continue.
But the harness layers are a different story entirely. Context governance requires deliberate architecture around how those three layers, global, runtime, and tenant, are structured and delivered. Data isolation requires access controls enforced at the system level. Observability comes from instrumentation built into the execution layer itself. None of these are capability problems. They are engineering and organizational problems, and they compound the longer you ignore them.
And then there is the one that rarely comes up: what happens when a provider goes down in the middle of a long-running enterprise task? Just last month, one of our executions stalled mid-run because a provider went down. The agent did not switch. It just waited. The harness needs to handle this, which means being built to be model agnostic by design, not just resilient when things go wrong. That requires building beyond hard dependencies on any single provider, and no amount of capability improvement changes that because a system getting better cannot replace itself with something else when it goes offline.
What I have come to believe, after watching this play out across enough production environments, is that capability was never the missing ingredient. A capable agent inside a poorly governed system is still a poorly governed system.
The Harness Is the Product
Over time, our focus shifted from building agents to building the systems that make agents reliable in production. We stopped thinking of evaluation, governance, and observability as separate problems and started thinking of them as the agent harness: the layers that make an agent trustworthy rather than just capable.
The harness has three parts that have to work together. There is a proactive layer: the testing infrastructure that detects when something in the product changed and surfaces what those changes will break before anything reaches production. There is a runtime layer: the governance controls that ensure the right context, the right constraints, and the right permissions are active for each specific execution, not assumed to be there from a document written months ago. And there is a reactive layer: the observability that captures not just what the agent did but why it made each decision, so when something goes wrong you can understand it, explain it, and fix it properly.
These layers do not make the agent more capable. They make the agent trustworthy. And trustworthy, it turns out, is worth more in production than capable.
That shift didn't come from a roadmap. Every layer we added, every guardrail we built, every piece of infrastructure we put in place came from seeing what happened when it wasn't there.
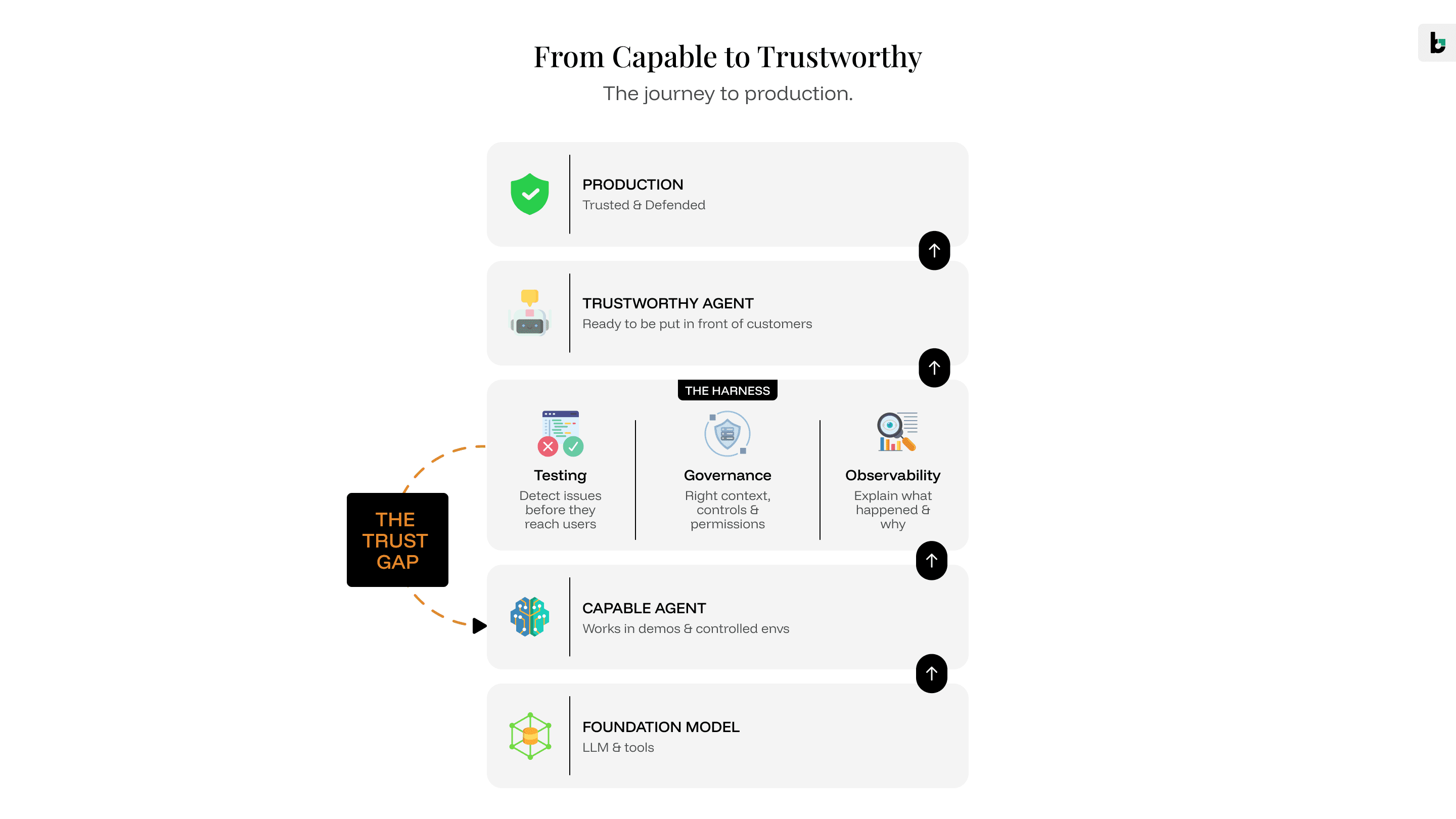
None of those layers make an agent more capable.
What they do is make it trustworthy. And that distinction matters more than most teams realise.
Across enterprise AI, building has become dramatically faster. Getting something to work is no longer the hard part. The harder challenge is crossing the gap between "this works" and "we're comfortable putting this in front of customers."
That's the gap where most projects stall. Not because the technology isn't ready, but because the trust around it isn't.
The teams that successfully ship won't necessarily be the ones with the most advanced models or the most impressive demos. They'll be the ones that recognise earlier that building an agent and running one in production are different problems.
Capability gets you through Build and Validate.
Trust gets you through Deploy.
The harness is how you get there.
This article was originally published on LinkedIn by Rakesh Vaddadi, CEO & Co-Founder of Beacon.li - https://www.linkedin.com/pulse/what-building-enterprise-ai-taught-us-why-agents-fail-rakesh-vaddadi-qmkkf/
This piece is a reflection on what building enterprise AI taught us about production. The patterns behind agent failures, the infrastructure they exposed, and why capability alone was never enough.
You'll learn:
Why execution is where most agents fail
How context should be layered for production
Why evaluation, governance, and observability create trust
Why the harness is ultimately the product
Every major technology wave has two chapters. The first is about the capability. The second is about the infrastructure that makes that capability reliable enough to actually use.
We are deep into the first chapter of the agent era. Teams are executing multi-step workflows with a fluency that would have seemed implausible three years ago. Hundreds of teams have shipped agents into production. Venture capital has poured in. The demos are genuinely impressive.
And yet the failure rates in production remain stubbornly high. Because the industry is still treating agents as a capability problem when what they actually need is an infrastructure problem solved.
The teams that have been building in enterprise AI long enough have quietly moved past the question of capability. They are working on something harder and less glamorous: the harness around the agent. The governance layer. The testing infrastructure. The observability that lets you explain what your agent did and why when an enterprise customer asks. This is the work that determines whether an agent survives contact with the real world.
We learned this the hard way, across dozens of production incidents where everything performed exactly as expected and the system still failed. The structure around it wasn't there. That gap, between a capable agent and a trustworthy one, is what we have spent the last few years building toward.
The Problem Was Never the Brain
When an agent handles a complex enterprise workflow, it isn't doing one thing. It is doing ten or fifteen things in sequence, each depending on the one before it, each producing context that shapes what should come next. That is where most agents actually break. In the execution structure, not the reasoning.
We started calling this the OCD framework, because it captures three distinct failure patterns we kept seeing in the wild.
Order of Execution. Enterprise workflows are rarely a clean list of steps you run top to bottom. They have hidden dependencies. Step three might need data that only becomes available after step six runs. An agent that doesn't recognize this will barrel through in the wrong order, hit a dead end, and either stall completely or keep going on whatever incomplete foundation it has. That is a sequencing failure, and it is remarkably common even in workflows that look simple on paper.
Contextual Execution. A plan that makes sense at the start of a run can become completely wrong three steps in. Every action produces new information, and that information should change what happens next. A good agent reads what the environment is telling it and adjusts. A brittle agent commits to the original plan no matter what signals it gets along the way. Think of a surgeon who keeps operating after discovering the patient's anatomy is different than the scans suggested. The problem isn't skill. It's rigidity in the face of new information.
Depth of Execution. Knowing what to do and knowing how far to go are two different skills. Some tasks genuinely need twenty steps done carefully. Others need twelve done well. An agent that stops too early leaves the job unfinished in ways that aren't immediately obvious. One that goes too far starts activating downstream processes that weren't supposed to run yet. Neither failure looks dramatic from the outside, which is exactly what makes both of them so easy to miss until real damage is done.
Every production incident we have investigated traces back to at least one of these three patterns. The execution structure was fragile.
Agents Break When Your Product Moves Forward Without Them
Here is something nobody tells you when you ship your first agent into production: the agent you built last month is quietly becoming wrong today.
Products evolve. Features change. Logic shifts in ways that don't always produce a changelog. Agents, left on their own, keep executing against a version of the world that no longer exists.
We found two very different ways this plays out, and they require completely different responses.
The first is when the product visibly changes. A new feature ships, a tool gets modified, a workflow is redesigned. These failures at least leave a paper trail. You can point to what changed, test against the new behavior, and catch breakage before it reaches users. Painful, but navigable.
The second kind is trickier. Nothing new got shipped. No APIs changed. But somewhere under the hood, the way things connect started working a little differently. The product looks the same. The agent's knowledge looks the same. The gap between them, however, has been growing for weeks. You find out when something fails in a way that looks like an error but is really just the world having moved on without the agent noticing.
This is why evaluation harnesses are infrastructure, not a feature you add later. The final output alone cannot tell you whether the agent arrived there correctly. Two completely different paths through a workflow can produce the same answer. One of them was sound. The other was a lucky mistake. You need to watch the path, not just the destination.
The Agent That Works in Europe Breaks in Singapore
Most people imagine agent failures as technical events. A bad prompt. A missed step. What we found in enterprise deployments is that the most expensive failures are organizational. They are governance failures.
We operate across industries and geographies. The same agent can work correctly in one regulatory environment and cause real problems in another. Because the rules and constraints it was operating under were never right for that context to begin with.
You cannot hand an agent a large document full of every possible rule for every possible situation and expect it to always surface the right ones. That is not how context works at scale. What you need is a way to deliver the right knowledge to the right execution at the right time, based on who is running it, where they are, and what is actually permitted for them.
The way we think about this is three distinct context layers.
Global context is the product and process knowledge that applies universally.
Runtime context is added dynamically to each execution based on the client, geography, and the constraints for that run.
Tenant context is the implementation knowledge specific to how a particular client has configured the system.
Each layer serves a different purpose. Without the boundaries between them, agents start bleeding context across accounts and regions. Rules meant for one client quietly get applied to another. Constraints designed for one geography creep into a different one. We have watched this happen in production. It is not theoretical.
The data access problem lives in the same territory. Agents have tool access, and they will use it broadly if nothing stops them. An agent operating with looser permissions than the underlying platform it sits within has effectively created a parallel access path into the system, whether anyone intended that or not. The architectural decision we made early was to not build a separate access control layer for the agent layer at all. The agent inherits the security rules that already exist in the platform and operates entirely within them. If a person cannot perform an action in the platform, the agent working on their behalf cannot either. Security is not something you bolt on afterward. It needs to be a property the system is born with.
A Log Is Not the Same Thing as Understanding
There is a phrase I keep coming back to: if you cannot explain what the agent did and why, you do not have an enterprise product. You have a prototype with an enterprise price tag.
A log that says "executed step seven" tells you almost nothing. Real observability means capturing the reasoning behind each decision. What was the agent looking at when it chose that path? What did it interpret from the step before? Why did it stop where it stopped?
Without this, investigating a failure becomes forensics on an incomplete record. You are sifting through what was captured trying to reconstruct a decision process that was never properly written down. In regulated industries, that is a compliance problem. In any enterprise context, it is a trust problem. And trust lost over a poorly explained agent action is very slow to come back.
Rollouts belong in the same conversation. Flipping from a test environment to full production is not a deployment strategy. It is a gamble. The right approach is gradual: ship to a small slice, watch behavior closely, expand only once you are confident. This is how careful engineering teams have shipped software for decades. The discipline is identical. What has changed is that when an agent acts, it does not just display something on a screen. It does things in the world.
Better Models Don't Create Trust
Things are improving fast and it is tempting to believe that capability gains will eventually wash away the operational problems underneath.
The execution layer, the sequencing, the mid-run adjustments, the depth calibration, those do get better as the underlying capability improves. We have seen it already and it will continue.
But the harness layers are a different story entirely. Context governance requires deliberate architecture around how those three layers, global, runtime, and tenant, are structured and delivered. Data isolation requires access controls enforced at the system level. Observability comes from instrumentation built into the execution layer itself. None of these are capability problems. They are engineering and organizational problems, and they compound the longer you ignore them.
And then there is the one that rarely comes up: what happens when a provider goes down in the middle of a long-running enterprise task? Just last month, one of our executions stalled mid-run because a provider went down. The agent did not switch. It just waited. The harness needs to handle this, which means being built to be model agnostic by design, not just resilient when things go wrong. That requires building beyond hard dependencies on any single provider, and no amount of capability improvement changes that because a system getting better cannot replace itself with something else when it goes offline.
What I have come to believe, after watching this play out across enough production environments, is that capability was never the missing ingredient. A capable agent inside a poorly governed system is still a poorly governed system.
The Harness Is the Product
Over time, our focus shifted from building agents to building the systems that make agents reliable in production. We stopped thinking of evaluation, governance, and observability as separate problems and started thinking of them as the agent harness: the layers that make an agent trustworthy rather than just capable.
The harness has three parts that have to work together. There is a proactive layer: the testing infrastructure that detects when something in the product changed and surfaces what those changes will break before anything reaches production. There is a runtime layer: the governance controls that ensure the right context, the right constraints, and the right permissions are active for each specific execution, not assumed to be there from a document written months ago. And there is a reactive layer: the observability that captures not just what the agent did but why it made each decision, so when something goes wrong you can understand it, explain it, and fix it properly.
These layers do not make the agent more capable. They make the agent trustworthy. And trustworthy, it turns out, is worth more in production than capable.
That shift didn't come from a roadmap. Every layer we added, every guardrail we built, every piece of infrastructure we put in place came from seeing what happened when it wasn't there.
None of those layers make an agent more capable.
What they do is make it trustworthy. And that distinction matters more than most teams realise.
Across enterprise AI, building has become dramatically faster. Getting something to work is no longer the hard part. The harder challenge is crossing the gap between "this works" and "we're comfortable putting this in front of customers."
That's the gap where most projects stall. Not because the technology isn't ready, but because the trust around it isn't.
The teams that successfully ship won't necessarily be the ones with the most advanced models or the most impressive demos. They'll be the ones that recognise earlier that building an agent and running one in production are different problems.
Capability gets you through Build and Validate.
Trust gets you through Deploy.
The harness is how you get there.
This article was originally published on LinkedIn by Rakesh Vaddadi, CEO & Co-Founder of Beacon.li - https://www.linkedin.com/pulse/what-building-enterprise-ai-taught-us-why-agents-fail-rakesh-vaddadi-qmkkf/








