AI Orchestration
Enterprise Software Doesn't Need More Dashboards. It Needs Operational Memory




Somewhere right now, a VP of Professional Services is walking into a QBR with a slide deck that shows implementation health by account. Green, yellow, red. Three of the reds are clients who were supposed to go live six weeks ago. Two of the greens are clients who went live on time but whose hypercare queues are still overflowing with tickets that trace back to configuration decisions nobody documented.
The deck will take forty minutes. Nobody in that room will leave knowing why the reds are red, whether the same thing will happen next quarter, or what specifically the team should do differently. The dashboard told everyone what h
appened. It has nothing to say about why, and nothing at all about what the organization learned.
That is the part that keeps not getting fixed.
Why has the implementation failure rate barely moved in ten years?
Gartner's projection for 2027 is that more than 70% of recently implemented ERP initiatives will fail to fully meet their original business case goals. If you work in enterprise software and you find that number surprising, you have not been in enough post-mortems.
What is actually surprising is that this number has stayed roughly where it was a decade ago, despite the industry spending enormous effort on the tooling around implementation. Better project management software. Richer dashboards. Health scores. Customer success platforms that aggregate signals from across the customer lifecycle.
None of it has moved the number.
The instinct when a number like that refuses to move is to ask what the tooling is still missing. More data, more visibility, smarter alerts. But that instinct assumes the problem is informational. That if someone in the Monday morning meeting had one more metric, or a better-organized dashboard, the implementation would have gone differently.
Most of the people who have actually run complex enterprise implementations know that is not quite right. The dashboard is rarely the thing that was missing. What was missing was something older and more specific: organizational memory. The accumulated, accessible record of what the team learned the last time they did this.
What does an implementation team actually rely on?
There is a version of this that sounds abstract, so here is the concrete version.
An experienced implementation consultant on a payroll software deployment knows something that is genuinely valuable and genuinely hard to replace. She knows that for clients in certain industries, the way the system handles leave accruals for part-time employees requires a specific configuration sequence that the standard documentation skips. She knows this because she hit it three implementations ago, spent two days figuring out what was wrong, and has not forgotten it since.
She also knows which questions to ask in the first discovery call that will surface the edge cases before configuration begins rather than after. She knows which UAT failures are cosmetic and which ones indicate something structural in the setup. She knows that when this particular client type asks for a certain kind of reporting, what they actually want is usually something slightly different that needs to be clarified early or it becomes a hypercare problem.
None of this is in the dashboard. None of it is in the ticket system. It is in her head, and it got there through a series of expensive mistakes that the organization paid for once and has no reliable way to benefit from again.
When she leaves, and she will eventually leave, that knowledge goes with her. The next consultant on that client type starts the same expensive discovery process from the beginning. The organization does not get progressively better at implementations over time. It gets the same implementation, repeatedly, at roughly the same cost and the same risk, because the learning from each cycle evaporates instead of accumulating.
This is not a people problem or a training problem. It is a structural problem with where knowledge lives.
Where is implementation knowledge actually stored right now?
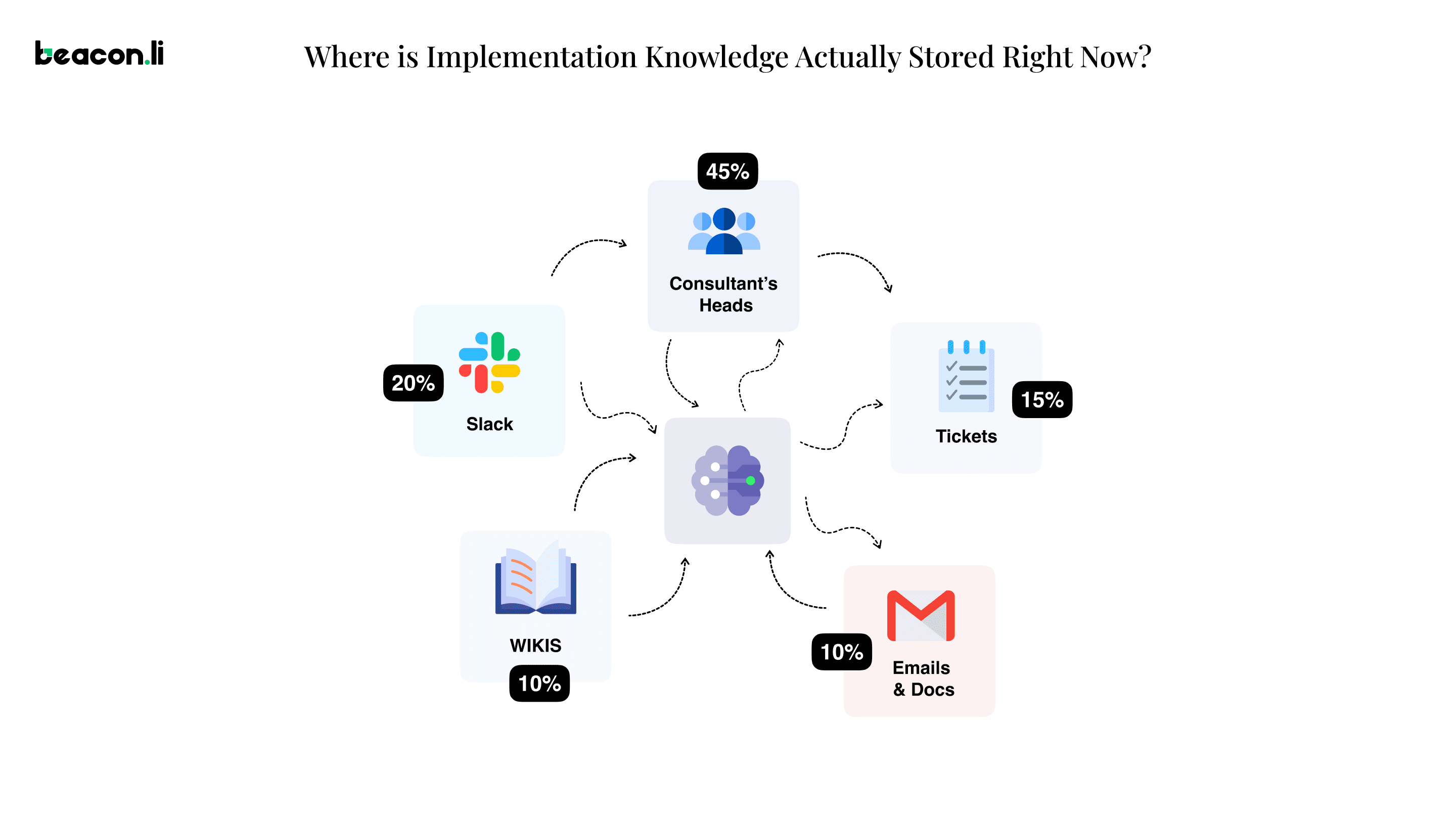
The honest answer is: scattered across places that were not designed to hold it.
Some of it is in Slack. The configuration decision that two consultants worked out in a thread at 11pm on a Wednesday is technically still there, three years later, somewhere. The escalation exchange where someone explained exactly why the client's approval workflow had to be rebuilt from scratch is in a channel that may or may not still exist. Searchable in theory. In practice, nobody goes back into old Slack threads to prepare for a new deployment.
Some of it is in tickets. Closed tickets with a summary in the resolution field that says something like "resolved configuration mismatch." What configuration. Which client requirement caused it. What the consultant actually changed and why. That context either made it into the notes or it didn't, and the honest answer is that it usually didn't, because the consultant was moving on to the next thing.
Some of it is in wikis. The implementation playbook that someone wrote eighteen months ago, that was accurate when it was written, that has not been updated since two major product releases, and that covers the standard case in reasonable detail while saying essentially nothing about any of the edge cases that actually determine whether a complex deployment succeeds or fails.
The rest of it is in people. In the institutional memory of whoever has been around long enough to have seen a given failure mode before. This is the most accurate and the most current version of the organization's implementation knowledge. It is also the one that disappears when someone takes a new job.
The result is that implementations don't compound. Every complex deployment is effectively the first one in terms of how much the team has to figure out on their own. The same ambiguous requirements get misread. The same configuration sequence breaks the same way. The same escalation patterns repeat. A team that has run fifty deployments does not perform dramatically better than a team that has run five, because the fifty deployments did not produce a usable record of what was learned. They produced fifty individual experiences that mostly stayed with the individuals who had them.
What does operational memory actually mean?
It is worth being specific here because the phrase can slide into something vague if you let it.
Operational memory, as a design principle for implementation systems, means that decisions are captured as data alongside the events they caused. When a consultant interprets an ambiguous requirement a certain way and configures the system accordingly, that interpretation gets recorded with enough context that someone coming to that account two years later can understand what was decided and why. When a configuration fails and gets corrected, the failure and the correction and the reasoning behind it become part of the permanent record of that deployment.
The distinction that matters is between logging what happened and capturing why. Current systems do a reasonable job of the former. Someone changed this field on this date. This ticket was opened and closed. This test case failed. But the causal layer, the decision logic that connects events to each other and explains why the implementation went the way it did, almost never gets captured in a form that compounds.
The other piece is that patterns need to become visible across deployments, not just within them. If a particular failure mode shows up on one implementation, it might be a quirk of that client. If it shows up on three implementations in the same vertical, it is probably something about how that client type uses the product. By the fifth or sixth time, it is a known pattern with a known resolution path, and ideally that knowledge is available to the consultant walking into their first deployment with a similar client. Today, reaching that point requires the institutional memory of someone who happened to be present for enough of those deployments. Operational memory means the system reaches that point regardless of who is in the room.
How does operational memory affect revenue?

Here is where implementation usually gets reframed as a business conversation rather than an operations conversation, and it is worth being direct about the mechanism.
Every week that passes between contract signing and go-live is a week of booked revenue that has not converted to realized revenue. That gap has a real cost that most organizations undercount because it shows up diffusely: in strained customer relationships, in higher churn rates at first renewal, in post-go-live support queues that overflow and pull resources away from new deployments, in senior consultants who are tied up on implementations that should have closed months ago.
The conventional response to this is headcount. More consultants means more capacity means faster throughput. And that works, up to a point, but it does not solve the underlying problem because the underlying problem is not capacity. It is that every new deployment starts from roughly the same baseline regardless of how many deployments the organization has run before.
When implementation knowledge actually compounds, the economics look different. HighRadius went from four to five days of manual configuration to twenty-two minutes on a workflow covering 188 enrichment rules across seventeen customer entities. That is not a modest efficiency improvement. That is the difference between a process that takes days and one that takes minutes, because the logic from previous deployments was captured and reusable rather than sitting in someone's memory or reconstructed from scratch.
Darwin Box's leave module went from two weeks to half a day. Not because the product changed or the team got more experienced. Because the implementation approach, including the edge cases and the decision logic and the configuration sequence that works for that module, existed as a usable record rather than as tribal knowledge that had to be retrieved from whoever happened to know it.
The question those numbers answer is not "how much faster can we go?" It is "what is the cost of starting every implementation from the same baseline?" When the answer to that question is visible, the case for building for memory rather than measurement becomes straightforward.
So what does the system that actually captures this look like?
The systems of record era built enormous value by capturing knowledge about specific business functions and making it queryable. Salesforce for customers, Workday for employees, SAP for financials. Each of those platforms works because it treats the data from its domain as something worth capturing persistently rather than letting it live in spreadsheets and email threads and people's heads.
Implementation has never had that. The execution layer, the actual work of configuring, migrating, testing, and validating enterprise software, has always been treated as something people do, not something a system captures and learns from. The byproduct of that execution, the decisions and interpretations and failure patterns and resolution paths, has always been treated as ephemeral.
The gap is not a better dashboard or a smarter project management layer. Those exist and they have not closed it. The gap is a system that executes implementation work and captures the decision traces that make each deployment more valuable than the last. One where the intelligence from every engagement compounds into something the organization actually owns rather than something it borrows from whichever consultant happened to be there.
This is what Beacon is built to do.
Beacon is the AI implementation orchestration platform that automates the actual execution work of enterprise software deployments, from requirements capture and configuration through data migration, testing, cutover, and hypercare, without requiring API keys, backend access, or engineering lift from the vendor. It learns how a product works through the UI, executes implementations using the same server calls the product already makes, and captures the decision traces, exception patterns, and resolution paths that compound into a reusable implementation context graph.
The results from live deployments are specific. HighRadius saw 188 enrichment rules across 17 customer entities configured in 22 minutes versus 4 to 5 days manually, an 85% reduction in configuration time. Darwin Box's leave module implementation dropped from two weeks to half a day. Every Beacon deployment enriches the intelligence layer for the next one.
This is what happens when implementation intelligence compounds. Every deployment contributes knowledge to the next deployment, execution improves over time, and operational memory becomes a direct driver of implementation speed, customer outcomes, and revenue realization.
What is the right question to ask now?
The organizations that will win in enterprise software over the next five years are not the ones that built the best dashboards. They are the ones that figured out how to make implementation intelligence compound, where each deployment makes the next one demonstrably better, and where the knowledge that has historically walked out the door stays in the system instead.
The question is not whether implementation can be automated. The early evidence is clear that it can. The question is whether your organization treats implementation as a cost to manage or an intelligence layer to build.
If it is the latter, the conversation about what that looks like in practice, on your actual product, in seven days, with no backend access required, is worth having.
Beacon is the AI implementation orchestration platform for enterprise software vendors. Every implementation Beacon runs compounds into a reusable execution intelligence layer that makes future deployments faster, safer, and more predictable.
Start with a 7-day POC on your product.
Somewhere right now, a VP of Professional Services is walking into a QBR with a slide deck that shows implementation health by account. Green, yellow, red. Three of the reds are clients who were supposed to go live six weeks ago. Two of the greens are clients who went live on time but whose hypercare queues are still overflowing with tickets that trace back to configuration decisions nobody documented.
The deck will take forty minutes. Nobody in that room will leave knowing why the reds are red, whether the same thing will happen next quarter, or what specifically the team should do differently. The dashboard told everyone what h
appened. It has nothing to say about why, and nothing at all about what the organization learned.
That is the part that keeps not getting fixed.
Why has the implementation failure rate barely moved in ten years?
Gartner's projection for 2027 is that more than 70% of recently implemented ERP initiatives will fail to fully meet their original business case goals. If you work in enterprise software and you find that number surprising, you have not been in enough post-mortems.
What is actually surprising is that this number has stayed roughly where it was a decade ago, despite the industry spending enormous effort on the tooling around implementation. Better project management software. Richer dashboards. Health scores. Customer success platforms that aggregate signals from across the customer lifecycle.
None of it has moved the number.
The instinct when a number like that refuses to move is to ask what the tooling is still missing. More data, more visibility, smarter alerts. But that instinct assumes the problem is informational. That if someone in the Monday morning meeting had one more metric, or a better-organized dashboard, the implementation would have gone differently.
Most of the people who have actually run complex enterprise implementations know that is not quite right. The dashboard is rarely the thing that was missing. What was missing was something older and more specific: organizational memory. The accumulated, accessible record of what the team learned the last time they did this.
What does an implementation team actually rely on?
There is a version of this that sounds abstract, so here is the concrete version.
An experienced implementation consultant on a payroll software deployment knows something that is genuinely valuable and genuinely hard to replace. She knows that for clients in certain industries, the way the system handles leave accruals for part-time employees requires a specific configuration sequence that the standard documentation skips. She knows this because she hit it three implementations ago, spent two days figuring out what was wrong, and has not forgotten it since.
She also knows which questions to ask in the first discovery call that will surface the edge cases before configuration begins rather than after. She knows which UAT failures are cosmetic and which ones indicate something structural in the setup. She knows that when this particular client type asks for a certain kind of reporting, what they actually want is usually something slightly different that needs to be clarified early or it becomes a hypercare problem.
None of this is in the dashboard. None of it is in the ticket system. It is in her head, and it got there through a series of expensive mistakes that the organization paid for once and has no reliable way to benefit from again.
When she leaves, and she will eventually leave, that knowledge goes with her. The next consultant on that client type starts the same expensive discovery process from the beginning. The organization does not get progressively better at implementations over time. It gets the same implementation, repeatedly, at roughly the same cost and the same risk, because the learning from each cycle evaporates instead of accumulating.
This is not a people problem or a training problem. It is a structural problem with where knowledge lives.
Where is implementation knowledge actually stored right now?
The honest answer is: scattered across places that were not designed to hold it.
Some of it is in Slack. The configuration decision that two consultants worked out in a thread at 11pm on a Wednesday is technically still there, three years later, somewhere. The escalation exchange where someone explained exactly why the client's approval workflow had to be rebuilt from scratch is in a channel that may or may not still exist. Searchable in theory. In practice, nobody goes back into old Slack threads to prepare for a new deployment.
Some of it is in tickets. Closed tickets with a summary in the resolution field that says something like "resolved configuration mismatch." What configuration. Which client requirement caused it. What the consultant actually changed and why. That context either made it into the notes or it didn't, and the honest answer is that it usually didn't, because the consultant was moving on to the next thing.
Some of it is in wikis. The implementation playbook that someone wrote eighteen months ago, that was accurate when it was written, that has not been updated since two major product releases, and that covers the standard case in reasonable detail while saying essentially nothing about any of the edge cases that actually determine whether a complex deployment succeeds or fails.
The rest of it is in people. In the institutional memory of whoever has been around long enough to have seen a given failure mode before. This is the most accurate and the most current version of the organization's implementation knowledge. It is also the one that disappears when someone takes a new job.
The result is that implementations don't compound. Every complex deployment is effectively the first one in terms of how much the team has to figure out on their own. The same ambiguous requirements get misread. The same configuration sequence breaks the same way. The same escalation patterns repeat. A team that has run fifty deployments does not perform dramatically better than a team that has run five, because the fifty deployments did not produce a usable record of what was learned. They produced fifty individual experiences that mostly stayed with the individuals who had them.
What does operational memory actually mean?
It is worth being specific here because the phrase can slide into something vague if you let it.
Operational memory, as a design principle for implementation systems, means that decisions are captured as data alongside the events they caused. When a consultant interprets an ambiguous requirement a certain way and configures the system accordingly, that interpretation gets recorded with enough context that someone coming to that account two years later can understand what was decided and why. When a configuration fails and gets corrected, the failure and the correction and the reasoning behind it become part of the permanent record of that deployment.
The distinction that matters is between logging what happened and capturing why. Current systems do a reasonable job of the former. Someone changed this field on this date. This ticket was opened and closed. This test case failed. But the causal layer, the decision logic that connects events to each other and explains why the implementation went the way it did, almost never gets captured in a form that compounds.
The other piece is that patterns need to become visible across deployments, not just within them. If a particular failure mode shows up on one implementation, it might be a quirk of that client. If it shows up on three implementations in the same vertical, it is probably something about how that client type uses the product. By the fifth or sixth time, it is a known pattern with a known resolution path, and ideally that knowledge is available to the consultant walking into their first deployment with a similar client. Today, reaching that point requires the institutional memory of someone who happened to be present for enough of those deployments. Operational memory means the system reaches that point regardless of who is in the room.
How does operational memory affect revenue?
Here is where implementation usually gets reframed as a business conversation rather than an operations conversation, and it is worth being direct about the mechanism.
Every week that passes between contract signing and go-live is a week of booked revenue that has not converted to realized revenue. That gap has a real cost that most organizations undercount because it shows up diffusely: in strained customer relationships, in higher churn rates at first renewal, in post-go-live support queues that overflow and pull resources away from new deployments, in senior consultants who are tied up on implementations that should have closed months ago.
The conventional response to this is headcount. More consultants means more capacity means faster throughput. And that works, up to a point, but it does not solve the underlying problem because the underlying problem is not capacity. It is that every new deployment starts from roughly the same baseline regardless of how many deployments the organization has run before.
When implementation knowledge actually compounds, the economics look different. HighRadius went from four to five days of manual configuration to twenty-two minutes on a workflow covering 188 enrichment rules across seventeen customer entities. That is not a modest efficiency improvement. That is the difference between a process that takes days and one that takes minutes, because the logic from previous deployments was captured and reusable rather than sitting in someone's memory or reconstructed from scratch.
Darwin Box's leave module went from two weeks to half a day. Not because the product changed or the team got more experienced. Because the implementation approach, including the edge cases and the decision logic and the configuration sequence that works for that module, existed as a usable record rather than as tribal knowledge that had to be retrieved from whoever happened to know it.
The question those numbers answer is not "how much faster can we go?" It is "what is the cost of starting every implementation from the same baseline?" When the answer to that question is visible, the case for building for memory rather than measurement becomes straightforward.
So what does the system that actually captures this look like?
The systems of record era built enormous value by capturing knowledge about specific business functions and making it queryable. Salesforce for customers, Workday for employees, SAP for financials. Each of those platforms works because it treats the data from its domain as something worth capturing persistently rather than letting it live in spreadsheets and email threads and people's heads.
Implementation has never had that. The execution layer, the actual work of configuring, migrating, testing, and validating enterprise software, has always been treated as something people do, not something a system captures and learns from. The byproduct of that execution, the decisions and interpretations and failure patterns and resolution paths, has always been treated as ephemeral.
The gap is not a better dashboard or a smarter project management layer. Those exist and they have not closed it. The gap is a system that executes implementation work and captures the decision traces that make each deployment more valuable than the last. One where the intelligence from every engagement compounds into something the organization actually owns rather than something it borrows from whichever consultant happened to be there.
This is what Beacon is built to do.
Beacon is the AI implementation orchestration platform that automates the actual execution work of enterprise software deployments, from requirements capture and configuration through data migration, testing, cutover, and hypercare, without requiring API keys, backend access, or engineering lift from the vendor. It learns how a product works through the UI, executes implementations using the same server calls the product already makes, and captures the decision traces, exception patterns, and resolution paths that compound into a reusable implementation context graph.
The results from live deployments are specific. HighRadius saw 188 enrichment rules across 17 customer entities configured in 22 minutes versus 4 to 5 days manually, an 85% reduction in configuration time. Darwin Box's leave module implementation dropped from two weeks to half a day. Every Beacon deployment enriches the intelligence layer for the next one.
This is what happens when implementation intelligence compounds. Every deployment contributes knowledge to the next deployment, execution improves over time, and operational memory becomes a direct driver of implementation speed, customer outcomes, and revenue realization.
What is the right question to ask now?
The organizations that will win in enterprise software over the next five years are not the ones that built the best dashboards. They are the ones that figured out how to make implementation intelligence compound, where each deployment makes the next one demonstrably better, and where the knowledge that has historically walked out the door stays in the system instead.
The question is not whether implementation can be automated. The early evidence is clear that it can. The question is whether your organization treats implementation as a cost to manage or an intelligence layer to build.
If it is the latter, the conversation about what that looks like in practice, on your actual product, in seven days, with no backend access required, is worth having.
Beacon is the AI implementation orchestration platform for enterprise software vendors. Every implementation Beacon runs compounds into a reusable execution intelligence layer that makes future deployments faster, safer, and more predictable.
Start with a 7-day POC on your product.








