How Are Companies Using AI for HRMS Implementation in 2026?




The companies getting this right are not using AI to assist their implementation teams. They are using AI to run implementations. That distinction matters more than it sounds, because the bottleneck in enterprise HRMS delivery has never been a lack of intelligent people. It has been the sheer volume of execution work that those people are forced to do by hand, across a lifecycle that is longer, more interdependent, and more technically complex than most enterprise software buyers ever anticipate.
In 2026, AI is being applied across the full HRMS implementation lifecycle. But the quality of that application varies enormously. Most of it is still surface-level. This article covers what the real bottlenecks are, where AI is making a measurable difference, and what separates assistive AI from execution AI in the context of enterprise HR systems.
Why HRMS Implementations Have Always Been Hard
HRMS platforms are not simple software. They are systems of record for some of the most complex, policy-heavy, and jurisdiction-sensitive data an organization manages: employee records, leave entitlements, org hierarchies, approval chains, payroll rules, compliance requirements, and role-based access controls. Every customer is different in ways that matter. A manufacturing organization with 4,000 employees across three states has a fundamentally different leave policy structure, approval hierarchy, and permission model than a technology company with 800 employees in two countries. Configuring the same HRMS for both is not a templated exercise. It requires interpreting requirements, making judgment calls about how to represent business rules inside the system, validating that data from legacy systems maps correctly, and testing every workflow before go-live under real access conditions.
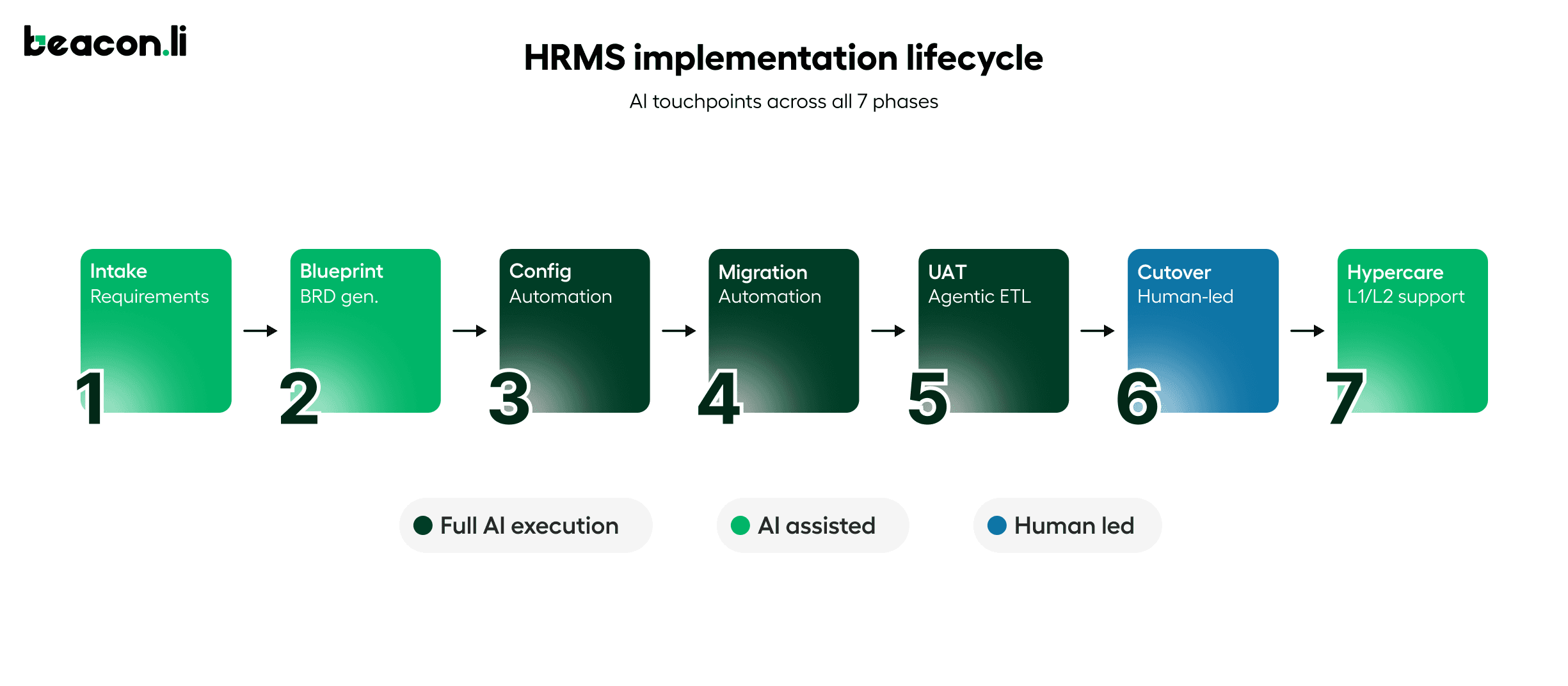
The implementation lifecycle typically runs across seven phases: intake and requirements capture, blueprint and BRD generation, environment configuration, data migration, UAT and testing, cutover, and hypercare. Each phase depends on the one before it. If requirements were captured poorly, configuration goes wrong. If configuration was done manually with undocumented decisions, testing is harder to design and easier to get wrong. If testing did not account for real user permissions, the failures appear after go-live, in production, in front of the customer's employees. The result is that HRMS implementations routinely take three to six months, cost more than budgeted, and leave implementation teams exhausted by the time the customer is live.
The more important question is where exactly those months go. The answer, consistently, is configuration and permissions.
Where AI Is Being Applied in HRMS Implementations in 2026
In 2026, AI is being used across the full HRMS implementation lifecycle, from the first intake call through post-go-live support. The application spans five distinct phases: requirements capture, environment configuration, data migration, testing and UAT, and hypercare. What separates meaningful AI adoption from surface-level tooling is whether AI is assisting humans with individual tasks or executing the implementation work itself. The phases below cover where each category of AI is showing up, what it is actually doing, and where the measurable impact is being seen.
Requirements Capture and Documentation in HRMS Implementations
The most common early application of AI in HRMS implementation is meeting transcription and requirements summarization. Tools like Gong and Granola can record implementation calls and produce summaries. This is useful, but it is a long way from solving the requirements problem. A transcript summary tells you what was discussed. It does not tell you which requirements contradict each other, which HRMS fields they map to, or what the configuration spec needs to look like.
More capable systems go further. They listen to implementation calls and produce structured requirement documents that map directly to the product being configured, consolidating inputs across multiple sessions, flagging ambiguities and contradictions between calls, and generating outputs in the vendor's own templates including business requirement documents, field-level configuration specs, permission matrices, and acceptance criteria. The difference between a transcript and a structured requirement spec is the difference between a record of a conversation and a document an engineer can execute against.
Configuration Automation in HRMS Implementations
Configuration is where the most implementation time is lost, and where AI is beginning to make measurable, documented impact. Manual configuration of a complex HRMS involves setting up leave policies, org structures, role and permission matrices, approval chains, workflow rules, and reporting hierarchies. Each setting carries dependencies on others. A leave policy configuration might depend on employee type, geography, seniority band, department, and approval chain structure simultaneously. Getting one condition wrong cascades into failures across the entire workflow.
In 2026, some implementations are running configuration automation through AI systems that can read a requirement spec, navigate the HRMS product interface, and execute configuration end-to-end without requiring the vendor to provide API access or backend credentials. The system learns the product through its UI, maps the server calls behind every action into executable tools, and runs configuration directly inside the product. Changes appear live in the product dashboard in real time.
The proof points are specific. Darwin Box, an HRMS platform serving enterprise customers across India and Southeast Asia, reduced configuration time for their leave policy module from approximately two weeks to half a day. The complexity involved cascading leave policy dependencies across employee types and geographies, precisely the kind of multi-condition, exception-heavy configuration that takes skilled consultants days to get right.
Data Migration in HRMS Implementations: Intelligent Failure Handling
Employee data migration is one of the highest-risk phases of any HRMS implementation. Moving records from a legacy HRIS, a set of spreadsheets, or another enterprise system into a new HRMS involves extraction, transformation, validation, and load. Errors at any stage can mean corrupted employee records, failed payroll runs, or missing leave balances that employees discover on their first day in the new system.
The traditional approach is largely manual: an implementation engineer writes migration scripts, a QA team validates the output, and the process iterates. AI is being applied here in two ways. First, to generate the extraction and transformation logic, reasoning about how fields in the source system map to fields in the target, handling edge cases, and flagging missing or ambiguous data before migration begins. Second, to handle failures intelligently. When a record fails to load, the system routes it back for diagnosis rather than halting the entire job. This combination of AI for reasoning and automation for execution allows migration jobs to scale to millions of records while still handling the kind of real-world data quality issues that pure automation scripts cannot resolve on their own.
Testing and UAT in HRMS Implementations: Generated from Live Configuration
UAT is the phase that most consistently overruns, for a reason that is structural rather than operational. Test cases are typically written manually, depend heavily on customer availability, and are not connected to the specific configuration that was actually built. A generic UAT template for an HRMS might cover the most common leave request scenarios. But if the customer has a four-level approval chain, a carryover policy that depends on employee grade, and a special provision for contractual workers, that generic template will miss most of what matters.
AI-driven testing generates test cases from the actual configuration applied, not from a library of generic scenarios. Because the system was part of the configuration process, it knows exactly what was configured. Test cases are specific to the client's setup, covering the workflows and edge cases relevant to their environment. When tests fail, the system categorizes the failure: expected negative test case, configuration error that can be fixed automatically, or client-driven change request that needs to be logged and timestamped. That distinction determines whether a failure triggers an automatic fix or a human decision point.
Hypercare and Post-Go-Live Support in HRMS Implementations
The weeks after go-live are expensive for HRMS vendors. End users generate high volumes of support tickets across two categories: how-do-I questions about navigating the new system, and something-is-wrong questions about leave balances, approvals, or workflow behavior. The first category can be handled by AI systems trained on the vendor's product knowledge base and the implementation documentation for that specific customer. The second is harder. It requires checking live configurations, reviewing workflow audit logs, and diagnosing mismatches between what was configured and what the user is experiencing. AI systems with access to the full implementation context can diagnose and resolve a significant proportion of these tickets without human escalation.
Why Permissions Are the Hardest Problem in HRMS Implementation
Permissions are the most underestimated layer in HRMS implementation and the most common source of post-go-live failures. Most implementation teams treat permissions as a configuration task that happens once, early in the project, and then gets tested at the end. That approach produces systems that look correct in isolation and break under real operating conditions.
A typical enterprise HRMS needs to handle role hierarchies across managers, HR business partners, finance, payroll, and leadership. It needs region-specific access rules driven by local compliance requirements, where an HR manager in Germany cannot see compensation data for employees in the United States in the same way that a counterpart in Singapore can. It needs data segmentation for sensitive fields including compensation, performance ratings, disciplinary records, and medical accommodations. It needs temporary and exception-based access for audit windows, organizational transitions, parole access for departing managers, and special workflows around M&A or restructuring events.
Defining these rules in a requirements document is straightforward. Applying them consistently across configuration, data migration, testing, and workflow validation is not.
Permissions are not a design problem in HRMS. They are an execution problem.
Most HRMS implementations fail not in defining access rules, but in applying them consistently across workflows, data structures, and regions throughout an implementation that spans months and involves dozens of configuration decisions made by different people at different times. A permission model that is not tested under real user workflows is a liability, not a safeguard.
Where Permission-Related Failures Happen in HRMS Implementations
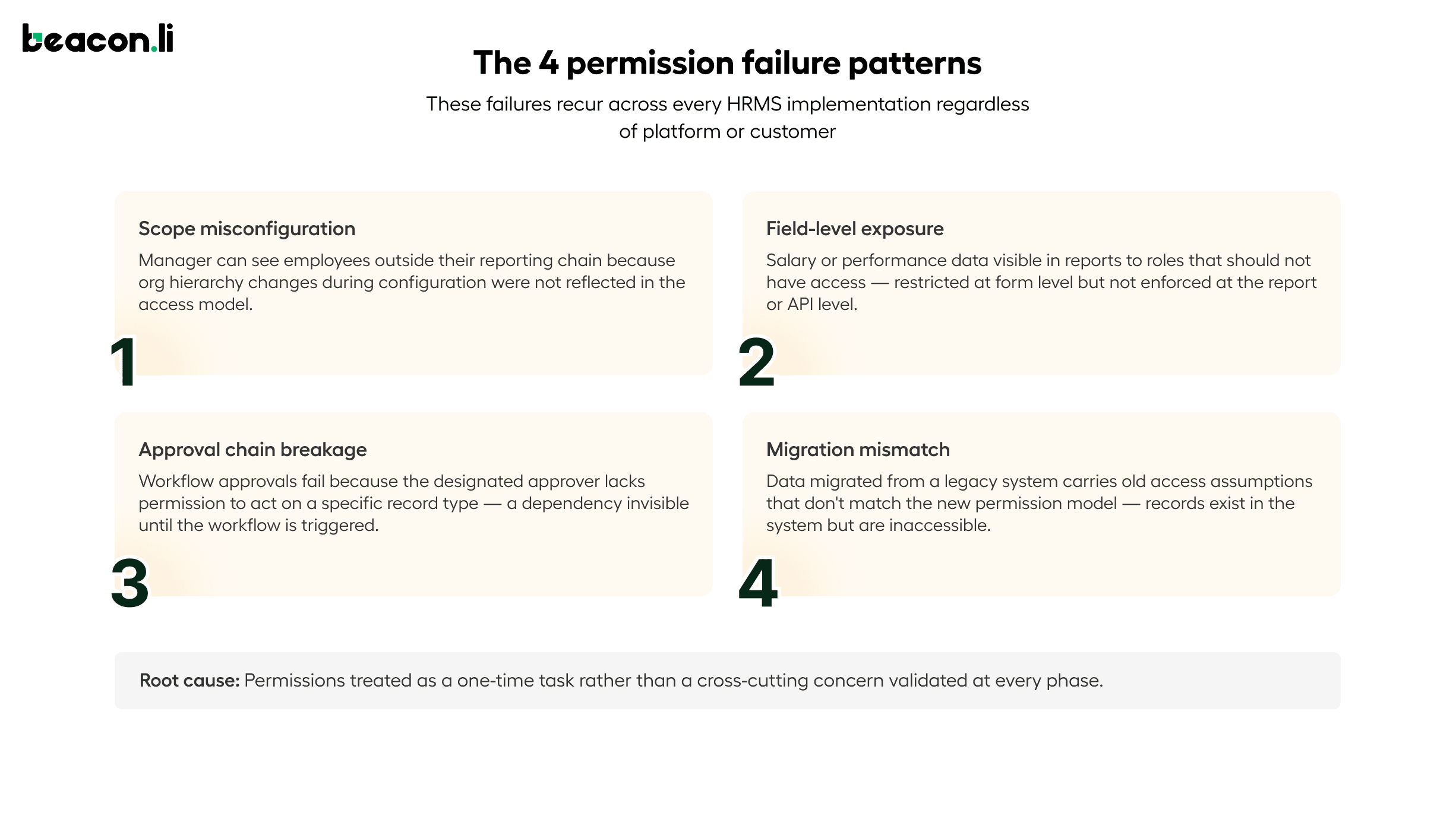
Permission failures in HRMS implementations fall into four consistent patterns. The first is scope misconfiguration, where a manager can see employees outside their reporting chain because org hierarchy changes made during configuration were not reflected in the access model. The second is field-level exposure, where salary or performance data is visible in certain views or reports to roles that should not have access, because field-level restrictions were configured at the form level but not enforced at the report or API level. The third is approval chain breakage, where workflow approvals fail because the user designated as an approver lacks the permission level required to act on a specific record type, a dependency that was not visible until the workflow was triggered. The fourth is migration-to-permission mismatch, where data that was migrated from a legacy system carries access assumptions from the old model that do not match the permission structure of the new system, producing records that are technically present but invisible or inaccessible to the users who need them.
These failures share a common cause: permissions were treated as a discrete configuration task rather than as a cross-cutting concern that needs to be validated at every phase of implementation.
HRMS Implementation Permissions at Scale: RBAC, ABAC, and Multi-Entity Complexity
Understanding how to evaluate permission handling in an HRMS implementation requires understanding the two dominant models and where each breaks down at scale.
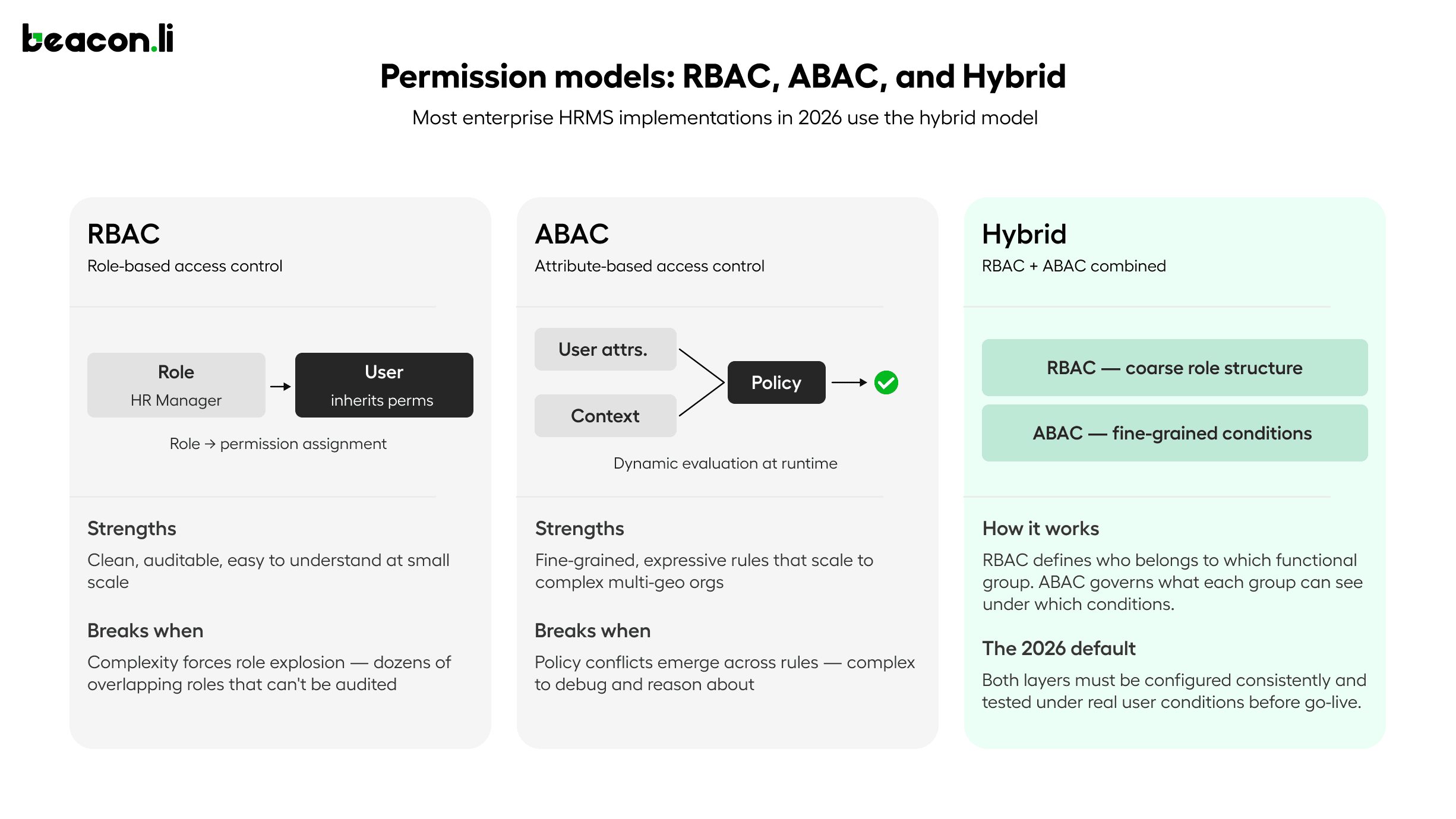
Role-Based Access Control assigns permissions to roles, and users inherit permissions through their role assignments. RBAC is clean, auditable, and easy to understand at small scale. It breaks down when organizations have enough complexity that the number of distinct permission combinations exceeds the number of manageable roles. An enterprise with 50 job families, 12 geographies, 4 management levels, and 6 functional departments cannot practically define a unique role for every combination of those dimensions. The result is role explosion, where administrators create dozens of overlapping roles with subtle differences, and the actual permission model becomes impossible to audit or reason about.
Attribute-Based Access Control evaluates permissions dynamically based on attributes of the user, the resource, and the context of the request. An ABAC policy might specify that an employee can view compensation records for direct reports in their own geography, but not for employees in other regions regardless of reporting relationship, and not during a compensation review lockout period. ABAC is more expressive and more maintainable at scale, but it requires a policy engine that evaluates permissions at request time rather than at assignment time, and it requires careful design to avoid policy conflicts where multiple rules produce contradictory access decisions for the same user and resource.
Most enterprise HRMS implementations in 2026 use a hybrid model: RBAC for the coarse-grained structure of who belongs to which functional group, and ABAC for the fine-grained rules about what each group can see and do under what conditions. The implementation challenge is ensuring that both layers are configured consistently, that the ABAC policies accurately reflect the requirements captured early in the project, and that the resulting permission model is tested under realistic conditions before go-live.
Multi-entity organizations add another layer of complexity. A holding company that operates multiple business units, each with its own HR policies, approval structures, and data residency requirements, needs a permission model that can enforce strict data isolation between entities while still allowing shared services functions to operate across them. Configuring this correctly requires understanding not just the permission rules but the data model of the HRMS itself, specifically how entities, employees, roles, and policies relate to each other in the system's internal structure.
Auditability as a First-Class Requirement in HRMS Implementations
Permission configuration is not just a functional requirement. In most jurisdictions where enterprise HRMS platforms operate, it is also a compliance requirement. GDPR requires that access to personal data be restricted to those with a legitimate purpose and that access be logged. SOX requires that compensation and financial data be accessible only to authorized personnel with documented controls. HIPAA applies to any health-related data stored in the HRMS. Local labor laws in markets including Germany, France, and Japan impose additional requirements around works council access, data localization, and employee data rights.
An HRMS implementation that does not produce a full audit trail of permission decisions, configuration changes, and data access is not production-ready in any enterprise context. The audit trail needs to capture not just what was configured, but why specific decisions were made, what alternatives were considered, and who approved them. This is the institutional record that protects the vendor and the customer in the event of a compliance audit or a data incident.
Where HRMS Implementations Break: Failure Patterns That Recur
Most failure analysis in HRMS implementation focuses on phases, asking which phase overran or which deliverable was late. The more useful frame is failure patterns, because the same failures recur across implementations regardless of which platform or which customer is involved.
Permission misconfiguration discovered post go-live is the most common and most expensive failure pattern. It typically surfaces when a manager notices they can see a record they should not, or an employee discovers they cannot access a workflow they need. By this point the system is in production, the fix requires configuration changes that need to be tested and validated before being applied, and every day the issue persists is a day the customer's trust is eroding.
UAT scenarios that do not reflect real access constraints are the root cause of most post-go-live permission issues. If testing was conducted under admin-level access, or if test cases were not designed to validate behavior under restricted user permissions, the failures that appear in production were present in the test environment but invisible because the test conditions were not realistic.
Data migration that violates the target permission model is a failure pattern specific to implementations that involve significant data from legacy systems. When employee records are migrated from a system with a different access model, the migration process can inadvertently produce data that is technically present in the new system but structured in a way that bypasses the intended permission rules. This is particularly common with hierarchical data like org structures and reporting relationships, where the legacy system's representation of a manager-employee relationship does not map cleanly to the new system's permission model.
Exception handling lost between phases is a failure pattern that produces subtle, hard-to-diagnose issues. During a complex implementation, many small decisions are made about how to handle edge cases: a role that doesn't fit the standard hierarchy, a policy exception for a specific employee group, a temporary access grant that was supposed to be revoked. If these decisions are not captured in a form that the next phase of the implementation can act on, they are lost. The configuration reflects the standard rules. The exceptions are invisible. The users who needed those exceptions experience failures that nobody can explain because nobody remembers the decision that created them.
What Most AI Approaches to HRMS Implementation Get Wrong
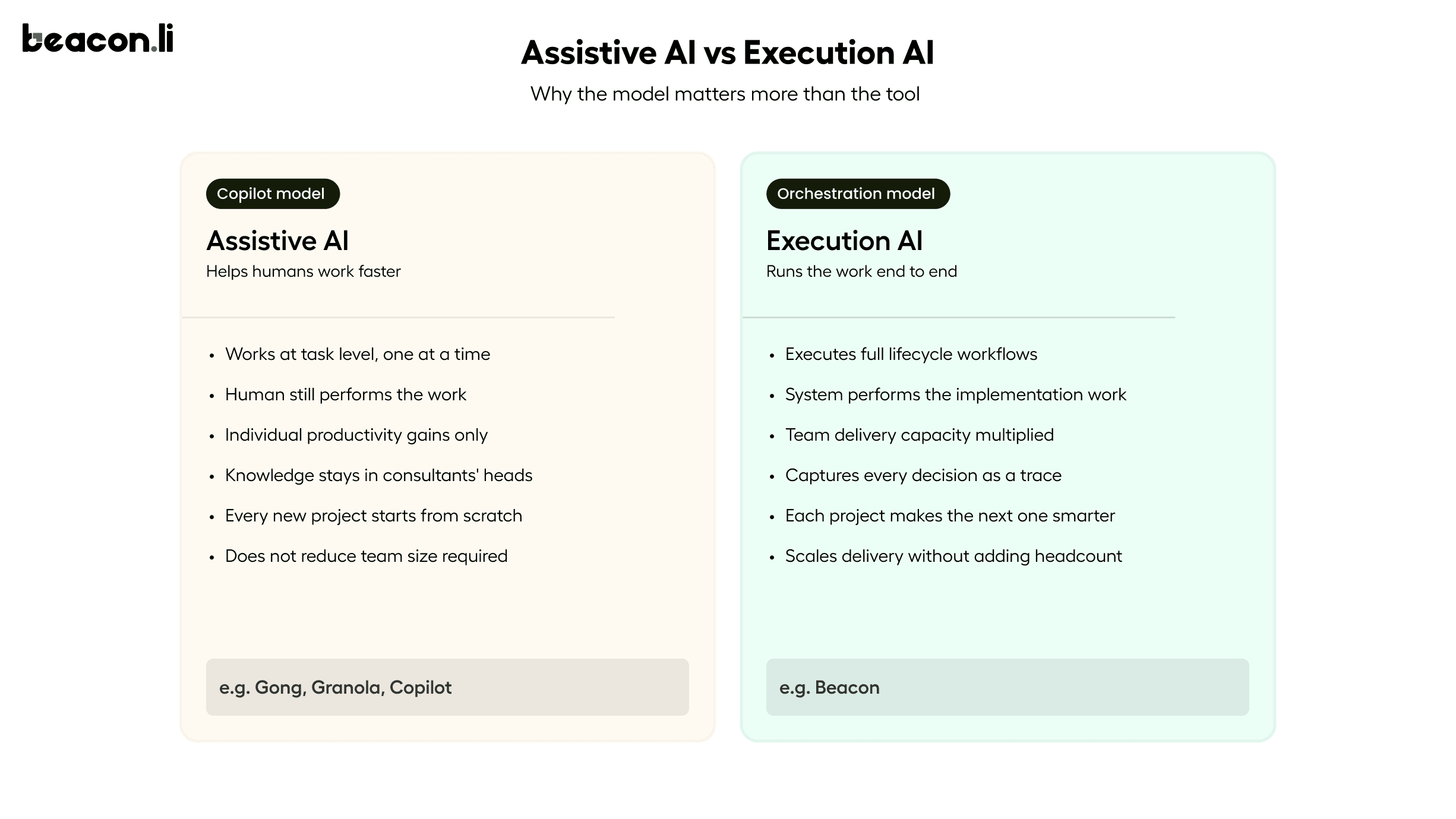
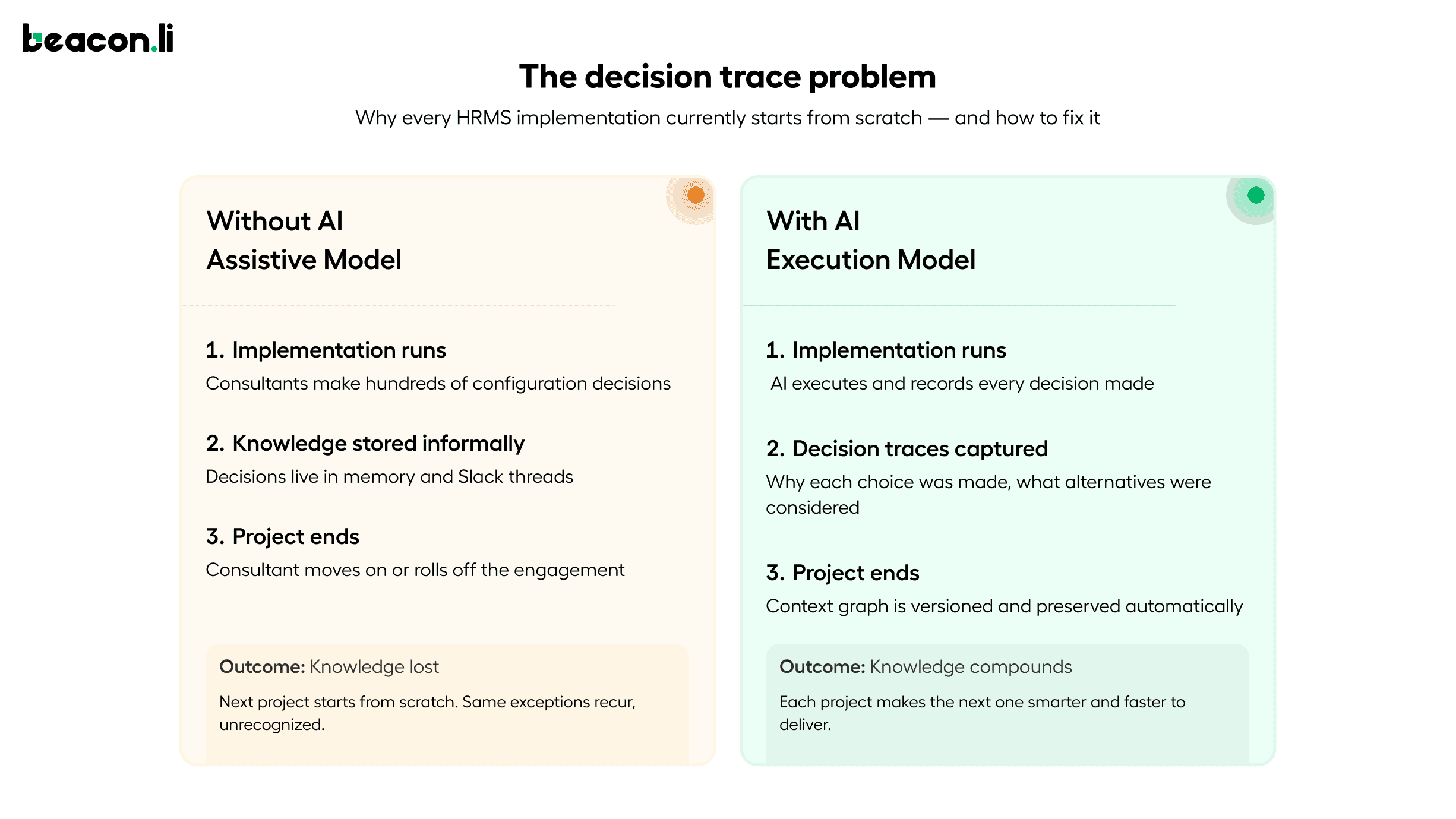
The majority of AI applied to HRMS implementation in 2026 is assistive rather than executive. It helps humans do the work faster. It does not change who does the work or solve the underlying problem of implementation knowledge being fragmented, undocumented, and lost when projects end.
When AI is applied as a copilot, suggesting or drafting at the task level, it improves individual productivity but does not change the structural problem. A consultant who configured a particular customer's leave policies and permission model three months ago carries context about why certain decisions were made. That context is not in any document. It lives in their memory, and when the project ends or the consultant moves on, it is gone. The next implementation starts from scratch.
This is why decision traces matter, and why the concept needs to be understood in concrete HR terms rather than as an abstract technical capability. A decision trace in the context of HRMS implementation is the structured record of why a leave policy exception was created for a specific employee group, why one region has a different approval chain than the standard model, why access to a particular data field was restricted for a specific role, and why a test case that initially failed was resolved by a configuration change rather than a requirement change. Most HRMS implementations lose this context entirely. That is why every project starts from scratch, why the same exceptions recur without recognition, and why the institutional knowledge that experienced implementation teams build up over years cannot be transferred or scaled.
The more durable application of AI captures decision traces as it executes, building a reusable implementation context graph that accumulates knowledge across every project. Requirements that were ambiguous and how they were resolved. Configurations that broke and why. Exceptions that recurred across multiple clients and how they were handled. Permission failures that appeared in testing and what the root cause was. This is what makes subsequent implementations faster and more reliable: not just because the AI executes individual tasks more quickly, but because it brings the accumulated context of every previous implementation to bear on the current one.
The Category Taking Shape: AI Orchestration for HRMS Implementations
What is emerging in 2026 is a new category of enterprise software that can be called AI implementation orchestration. These are not project management tools that track what human teams are doing. They are not copilots that assist with individual tasks. They are systems that execute the implementation work itself, end-to-end, with permission-aware execution as a first-class capability, while capturing the institutional knowledge that makes every future implementation faster and more reliable.
Beacon is the platform being built specifically for this category, with a focus on complex, vertical enterprise software including HRMS. It operates across the full implementation lifecycle, from listening to intake calls and generating structured requirement specs with permission matrices, through executing configuration inside the product UI, running agentic ETL for data migration, generating and executing customer-specific UAT under realistic permission conditions, supporting cutover, and handling post-go-live L1 and L2 support using the implementation context it built during delivery.
The architecture is UI-native, meaning Beacon learns the HRMS product by navigating its interface and mapping the server calls behind every action into executable tools. This requires no API access, no backend credentials, and no engineering effort from the vendor. A proof of concept runs in seven days on a demo instance of the vendor's product.
What makes this an orchestration platform rather than a collection of point tools is the connection between phases. Requirements inform configuration. Configuration state drives test case generation, including permission-specific scenarios. Test results and exception patterns feed into the hypercare knowledge base. The context from every phase compounds into a reusable implementation context graph. Every project makes the next one smarter.
What HRMS Vendors Should Be Asking About Their Implementation Approach
If you run professional services, implementation, or onboarding for an HRMS platform, the questions worth asking in 2026 are more specific than they were two years ago.
Where does implementation time actually go, and how much of it is in configuration and permission setup? Most teams know the answer intuitively but have not quantified it. The before-and-after contrast is where the business case for AI implementation automation becomes concrete and defensible.
What happens to implementation knowledge when a project ends? If the answer is that it lives in the consultant's memory and a few Slack threads, the organization has a scaling problem that headcount alone will not solve. Every new implementation starting from scratch is a direct cost of not capturing decision traces.
Are you automating tasks or automating the work? Copilots and meeting assistants improve efficiency at the task level. They do not change the structure of how implementations get done. The distinction matters when the goal is to scale delivery capacity without scaling headcount proportionally.
Can you prove value before committing? The most credible AI implementation platforms will run a proof of concept on the actual product, not a generic demo environment, in days rather than months. If a vendor cannot prove capability on a real instance of the HRMS before signing, that tells you something important about the maturity of what they are offering.
Summary: What AI Actually Changes About HRMS Implementations
AI is being applied to HRMS implementation across five phases in 2026: requirements capture, configuration, data migration, testing, and hypercare. The applications range from basic transcription and summarization to full lifecycle execution automation. The difference between assistive AI and execution AI is significant. Assistive AI makes human teams faster at individual tasks. Execution AI changes who does the work, captures the institutional context that those humans would otherwise carry in their heads, and compounds that knowledge across every future implementation.
Permissions are where the complexity is highest and where the failure rate is most consequential. A permission model that is designed correctly but implemented inconsistently across configuration, migration, and testing will fail in production. The HRMS implementations that are succeeding in 2026 are the ones that treat permission-aware execution as a first-class requirement from day one, test under real user conditions, and capture every exception and decision in a form that the next implementation can learn from.
The technology to do this exists. The proof points are documented. The category is forming now, and the vendors who move first will have compounding execution intelligence that their competitors will not be able to replicate by hiring more consultants or adding more copilots.
Beacon is the AI implementation orchestration platform for enterprise software vendors. It automates the full HRMS implementation lifecycle from requirements through hypercare, with permission-aware execution, agentic data migration, and configuration-specific UAT generation, without requiring API access or backend integration. Proof of concept in 7 days on your product.
The companies getting this right are not using AI to assist their implementation teams. They are using AI to run implementations. That distinction matters more than it sounds, because the bottleneck in enterprise HRMS delivery has never been a lack of intelligent people. It has been the sheer volume of execution work that those people are forced to do by hand, across a lifecycle that is longer, more interdependent, and more technically complex than most enterprise software buyers ever anticipate.
In 2026, AI is being applied across the full HRMS implementation lifecycle. But the quality of that application varies enormously. Most of it is still surface-level. This article covers what the real bottlenecks are, where AI is making a measurable difference, and what separates assistive AI from execution AI in the context of enterprise HR systems.
Why HRMS Implementations Have Always Been Hard
HRMS platforms are not simple software. They are systems of record for some of the most complex, policy-heavy, and jurisdiction-sensitive data an organization manages: employee records, leave entitlements, org hierarchies, approval chains, payroll rules, compliance requirements, and role-based access controls. Every customer is different in ways that matter. A manufacturing organization with 4,000 employees across three states has a fundamentally different leave policy structure, approval hierarchy, and permission model than a technology company with 800 employees in two countries. Configuring the same HRMS for both is not a templated exercise. It requires interpreting requirements, making judgment calls about how to represent business rules inside the system, validating that data from legacy systems maps correctly, and testing every workflow before go-live under real access conditions.
The implementation lifecycle typically runs across seven phases: intake and requirements capture, blueprint and BRD generation, environment configuration, data migration, UAT and testing, cutover, and hypercare. Each phase depends on the one before it. If requirements were captured poorly, configuration goes wrong. If configuration was done manually with undocumented decisions, testing is harder to design and easier to get wrong. If testing did not account for real user permissions, the failures appear after go-live, in production, in front of the customer's employees. The result is that HRMS implementations routinely take three to six months, cost more than budgeted, and leave implementation teams exhausted by the time the customer is live.
The more important question is where exactly those months go. The answer, consistently, is configuration and permissions.
Where AI Is Being Applied in HRMS Implementations in 2026
In 2026, AI is being used across the full HRMS implementation lifecycle, from the first intake call through post-go-live support. The application spans five distinct phases: requirements capture, environment configuration, data migration, testing and UAT, and hypercare. What separates meaningful AI adoption from surface-level tooling is whether AI is assisting humans with individual tasks or executing the implementation work itself. The phases below cover where each category of AI is showing up, what it is actually doing, and where the measurable impact is being seen.
Requirements Capture and Documentation in HRMS Implementations
The most common early application of AI in HRMS implementation is meeting transcription and requirements summarization. Tools like Gong and Granola can record implementation calls and produce summaries. This is useful, but it is a long way from solving the requirements problem. A transcript summary tells you what was discussed. It does not tell you which requirements contradict each other, which HRMS fields they map to, or what the configuration spec needs to look like.
More capable systems go further. They listen to implementation calls and produce structured requirement documents that map directly to the product being configured, consolidating inputs across multiple sessions, flagging ambiguities and contradictions between calls, and generating outputs in the vendor's own templates including business requirement documents, field-level configuration specs, permission matrices, and acceptance criteria. The difference between a transcript and a structured requirement spec is the difference between a record of a conversation and a document an engineer can execute against.
Configuration Automation in HRMS Implementations
Configuration is where the most implementation time is lost, and where AI is beginning to make measurable, documented impact. Manual configuration of a complex HRMS involves setting up leave policies, org structures, role and permission matrices, approval chains, workflow rules, and reporting hierarchies. Each setting carries dependencies on others. A leave policy configuration might depend on employee type, geography, seniority band, department, and approval chain structure simultaneously. Getting one condition wrong cascades into failures across the entire workflow.
In 2026, some implementations are running configuration automation through AI systems that can read a requirement spec, navigate the HRMS product interface, and execute configuration end-to-end without requiring the vendor to provide API access or backend credentials. The system learns the product through its UI, maps the server calls behind every action into executable tools, and runs configuration directly inside the product. Changes appear live in the product dashboard in real time.
The proof points are specific. Darwin Box, an HRMS platform serving enterprise customers across India and Southeast Asia, reduced configuration time for their leave policy module from approximately two weeks to half a day. The complexity involved cascading leave policy dependencies across employee types and geographies, precisely the kind of multi-condition, exception-heavy configuration that takes skilled consultants days to get right.
Data Migration in HRMS Implementations: Intelligent Failure Handling
Employee data migration is one of the highest-risk phases of any HRMS implementation. Moving records from a legacy HRIS, a set of spreadsheets, or another enterprise system into a new HRMS involves extraction, transformation, validation, and load. Errors at any stage can mean corrupted employee records, failed payroll runs, or missing leave balances that employees discover on their first day in the new system.
The traditional approach is largely manual: an implementation engineer writes migration scripts, a QA team validates the output, and the process iterates. AI is being applied here in two ways. First, to generate the extraction and transformation logic, reasoning about how fields in the source system map to fields in the target, handling edge cases, and flagging missing or ambiguous data before migration begins. Second, to handle failures intelligently. When a record fails to load, the system routes it back for diagnosis rather than halting the entire job. This combination of AI for reasoning and automation for execution allows migration jobs to scale to millions of records while still handling the kind of real-world data quality issues that pure automation scripts cannot resolve on their own.
Testing and UAT in HRMS Implementations: Generated from Live Configuration
UAT is the phase that most consistently overruns, for a reason that is structural rather than operational. Test cases are typically written manually, depend heavily on customer availability, and are not connected to the specific configuration that was actually built. A generic UAT template for an HRMS might cover the most common leave request scenarios. But if the customer has a four-level approval chain, a carryover policy that depends on employee grade, and a special provision for contractual workers, that generic template will miss most of what matters.
AI-driven testing generates test cases from the actual configuration applied, not from a library of generic scenarios. Because the system was part of the configuration process, it knows exactly what was configured. Test cases are specific to the client's setup, covering the workflows and edge cases relevant to their environment. When tests fail, the system categorizes the failure: expected negative test case, configuration error that can be fixed automatically, or client-driven change request that needs to be logged and timestamped. That distinction determines whether a failure triggers an automatic fix or a human decision point.
Hypercare and Post-Go-Live Support in HRMS Implementations
The weeks after go-live are expensive for HRMS vendors. End users generate high volumes of support tickets across two categories: how-do-I questions about navigating the new system, and something-is-wrong questions about leave balances, approvals, or workflow behavior. The first category can be handled by AI systems trained on the vendor's product knowledge base and the implementation documentation for that specific customer. The second is harder. It requires checking live configurations, reviewing workflow audit logs, and diagnosing mismatches between what was configured and what the user is experiencing. AI systems with access to the full implementation context can diagnose and resolve a significant proportion of these tickets without human escalation.
Why Permissions Are the Hardest Problem in HRMS Implementation
Permissions are the most underestimated layer in HRMS implementation and the most common source of post-go-live failures. Most implementation teams treat permissions as a configuration task that happens once, early in the project, and then gets tested at the end. That approach produces systems that look correct in isolation and break under real operating conditions.
A typical enterprise HRMS needs to handle role hierarchies across managers, HR business partners, finance, payroll, and leadership. It needs region-specific access rules driven by local compliance requirements, where an HR manager in Germany cannot see compensation data for employees in the United States in the same way that a counterpart in Singapore can. It needs data segmentation for sensitive fields including compensation, performance ratings, disciplinary records, and medical accommodations. It needs temporary and exception-based access for audit windows, organizational transitions, parole access for departing managers, and special workflows around M&A or restructuring events.
Defining these rules in a requirements document is straightforward. Applying them consistently across configuration, data migration, testing, and workflow validation is not.
Permissions are not a design problem in HRMS. They are an execution problem.
Most HRMS implementations fail not in defining access rules, but in applying them consistently across workflows, data structures, and regions throughout an implementation that spans months and involves dozens of configuration decisions made by different people at different times. A permission model that is not tested under real user workflows is a liability, not a safeguard.
Where Permission-Related Failures Happen in HRMS Implementations
Permission failures in HRMS implementations fall into four consistent patterns. The first is scope misconfiguration, where a manager can see employees outside their reporting chain because org hierarchy changes made during configuration were not reflected in the access model. The second is field-level exposure, where salary or performance data is visible in certain views or reports to roles that should not have access, because field-level restrictions were configured at the form level but not enforced at the report or API level. The third is approval chain breakage, where workflow approvals fail because the user designated as an approver lacks the permission level required to act on a specific record type, a dependency that was not visible until the workflow was triggered. The fourth is migration-to-permission mismatch, where data that was migrated from a legacy system carries access assumptions from the old model that do not match the permission structure of the new system, producing records that are technically present but invisible or inaccessible to the users who need them.
These failures share a common cause: permissions were treated as a discrete configuration task rather than as a cross-cutting concern that needs to be validated at every phase of implementation.
HRMS Implementation Permissions at Scale: RBAC, ABAC, and Multi-Entity Complexity
Understanding how to evaluate permission handling in an HRMS implementation requires understanding the two dominant models and where each breaks down at scale.
Role-Based Access Control assigns permissions to roles, and users inherit permissions through their role assignments. RBAC is clean, auditable, and easy to understand at small scale. It breaks down when organizations have enough complexity that the number of distinct permission combinations exceeds the number of manageable roles. An enterprise with 50 job families, 12 geographies, 4 management levels, and 6 functional departments cannot practically define a unique role for every combination of those dimensions. The result is role explosion, where administrators create dozens of overlapping roles with subtle differences, and the actual permission model becomes impossible to audit or reason about.
Attribute-Based Access Control evaluates permissions dynamically based on attributes of the user, the resource, and the context of the request. An ABAC policy might specify that an employee can view compensation records for direct reports in their own geography, but not for employees in other regions regardless of reporting relationship, and not during a compensation review lockout period. ABAC is more expressive and more maintainable at scale, but it requires a policy engine that evaluates permissions at request time rather than at assignment time, and it requires careful design to avoid policy conflicts where multiple rules produce contradictory access decisions for the same user and resource.
Most enterprise HRMS implementations in 2026 use a hybrid model: RBAC for the coarse-grained structure of who belongs to which functional group, and ABAC for the fine-grained rules about what each group can see and do under what conditions. The implementation challenge is ensuring that both layers are configured consistently, that the ABAC policies accurately reflect the requirements captured early in the project, and that the resulting permission model is tested under realistic conditions before go-live.
Multi-entity organizations add another layer of complexity. A holding company that operates multiple business units, each with its own HR policies, approval structures, and data residency requirements, needs a permission model that can enforce strict data isolation between entities while still allowing shared services functions to operate across them. Configuring this correctly requires understanding not just the permission rules but the data model of the HRMS itself, specifically how entities, employees, roles, and policies relate to each other in the system's internal structure.
Auditability as a First-Class Requirement in HRMS Implementations
Permission configuration is not just a functional requirement. In most jurisdictions where enterprise HRMS platforms operate, it is also a compliance requirement. GDPR requires that access to personal data be restricted to those with a legitimate purpose and that access be logged. SOX requires that compensation and financial data be accessible only to authorized personnel with documented controls. HIPAA applies to any health-related data stored in the HRMS. Local labor laws in markets including Germany, France, and Japan impose additional requirements around works council access, data localization, and employee data rights.
An HRMS implementation that does not produce a full audit trail of permission decisions, configuration changes, and data access is not production-ready in any enterprise context. The audit trail needs to capture not just what was configured, but why specific decisions were made, what alternatives were considered, and who approved them. This is the institutional record that protects the vendor and the customer in the event of a compliance audit or a data incident.
Where HRMS Implementations Break: Failure Patterns That Recur
Most failure analysis in HRMS implementation focuses on phases, asking which phase overran or which deliverable was late. The more useful frame is failure patterns, because the same failures recur across implementations regardless of which platform or which customer is involved.
Permission misconfiguration discovered post go-live is the most common and most expensive failure pattern. It typically surfaces when a manager notices they can see a record they should not, or an employee discovers they cannot access a workflow they need. By this point the system is in production, the fix requires configuration changes that need to be tested and validated before being applied, and every day the issue persists is a day the customer's trust is eroding.
UAT scenarios that do not reflect real access constraints are the root cause of most post-go-live permission issues. If testing was conducted under admin-level access, or if test cases were not designed to validate behavior under restricted user permissions, the failures that appear in production were present in the test environment but invisible because the test conditions were not realistic.
Data migration that violates the target permission model is a failure pattern specific to implementations that involve significant data from legacy systems. When employee records are migrated from a system with a different access model, the migration process can inadvertently produce data that is technically present in the new system but structured in a way that bypasses the intended permission rules. This is particularly common with hierarchical data like org structures and reporting relationships, where the legacy system's representation of a manager-employee relationship does not map cleanly to the new system's permission model.
Exception handling lost between phases is a failure pattern that produces subtle, hard-to-diagnose issues. During a complex implementation, many small decisions are made about how to handle edge cases: a role that doesn't fit the standard hierarchy, a policy exception for a specific employee group, a temporary access grant that was supposed to be revoked. If these decisions are not captured in a form that the next phase of the implementation can act on, they are lost. The configuration reflects the standard rules. The exceptions are invisible. The users who needed those exceptions experience failures that nobody can explain because nobody remembers the decision that created them.
What Most AI Approaches to HRMS Implementation Get Wrong
The majority of AI applied to HRMS implementation in 2026 is assistive rather than executive. It helps humans do the work faster. It does not change who does the work or solve the underlying problem of implementation knowledge being fragmented, undocumented, and lost when projects end.
When AI is applied as a copilot, suggesting or drafting at the task level, it improves individual productivity but does not change the structural problem. A consultant who configured a particular customer's leave policies and permission model three months ago carries context about why certain decisions were made. That context is not in any document. It lives in their memory, and when the project ends or the consultant moves on, it is gone. The next implementation starts from scratch.
This is why decision traces matter, and why the concept needs to be understood in concrete HR terms rather than as an abstract technical capability. A decision trace in the context of HRMS implementation is the structured record of why a leave policy exception was created for a specific employee group, why one region has a different approval chain than the standard model, why access to a particular data field was restricted for a specific role, and why a test case that initially failed was resolved by a configuration change rather than a requirement change. Most HRMS implementations lose this context entirely. That is why every project starts from scratch, why the same exceptions recur without recognition, and why the institutional knowledge that experienced implementation teams build up over years cannot be transferred or scaled.
The more durable application of AI captures decision traces as it executes, building a reusable implementation context graph that accumulates knowledge across every project. Requirements that were ambiguous and how they were resolved. Configurations that broke and why. Exceptions that recurred across multiple clients and how they were handled. Permission failures that appeared in testing and what the root cause was. This is what makes subsequent implementations faster and more reliable: not just because the AI executes individual tasks more quickly, but because it brings the accumulated context of every previous implementation to bear on the current one.
The Category Taking Shape: AI Orchestration for HRMS Implementations
What is emerging in 2026 is a new category of enterprise software that can be called AI implementation orchestration. These are not project management tools that track what human teams are doing. They are not copilots that assist with individual tasks. They are systems that execute the implementation work itself, end-to-end, with permission-aware execution as a first-class capability, while capturing the institutional knowledge that makes every future implementation faster and more reliable.
Beacon is the platform being built specifically for this category, with a focus on complex, vertical enterprise software including HRMS. It operates across the full implementation lifecycle, from listening to intake calls and generating structured requirement specs with permission matrices, through executing configuration inside the product UI, running agentic ETL for data migration, generating and executing customer-specific UAT under realistic permission conditions, supporting cutover, and handling post-go-live L1 and L2 support using the implementation context it built during delivery.
The architecture is UI-native, meaning Beacon learns the HRMS product by navigating its interface and mapping the server calls behind every action into executable tools. This requires no API access, no backend credentials, and no engineering effort from the vendor. A proof of concept runs in seven days on a demo instance of the vendor's product.
What makes this an orchestration platform rather than a collection of point tools is the connection between phases. Requirements inform configuration. Configuration state drives test case generation, including permission-specific scenarios. Test results and exception patterns feed into the hypercare knowledge base. The context from every phase compounds into a reusable implementation context graph. Every project makes the next one smarter.
What HRMS Vendors Should Be Asking About Their Implementation Approach
If you run professional services, implementation, or onboarding for an HRMS platform, the questions worth asking in 2026 are more specific than they were two years ago.
Where does implementation time actually go, and how much of it is in configuration and permission setup? Most teams know the answer intuitively but have not quantified it. The before-and-after contrast is where the business case for AI implementation automation becomes concrete and defensible.
What happens to implementation knowledge when a project ends? If the answer is that it lives in the consultant's memory and a few Slack threads, the organization has a scaling problem that headcount alone will not solve. Every new implementation starting from scratch is a direct cost of not capturing decision traces.
Are you automating tasks or automating the work? Copilots and meeting assistants improve efficiency at the task level. They do not change the structure of how implementations get done. The distinction matters when the goal is to scale delivery capacity without scaling headcount proportionally.
Can you prove value before committing? The most credible AI implementation platforms will run a proof of concept on the actual product, not a generic demo environment, in days rather than months. If a vendor cannot prove capability on a real instance of the HRMS before signing, that tells you something important about the maturity of what they are offering.
Summary: What AI Actually Changes About HRMS Implementations
AI is being applied to HRMS implementation across five phases in 2026: requirements capture, configuration, data migration, testing, and hypercare. The applications range from basic transcription and summarization to full lifecycle execution automation. The difference between assistive AI and execution AI is significant. Assistive AI makes human teams faster at individual tasks. Execution AI changes who does the work, captures the institutional context that those humans would otherwise carry in their heads, and compounds that knowledge across every future implementation.
Permissions are where the complexity is highest and where the failure rate is most consequential. A permission model that is designed correctly but implemented inconsistently across configuration, migration, and testing will fail in production. The HRMS implementations that are succeeding in 2026 are the ones that treat permission-aware execution as a first-class requirement from day one, test under real user conditions, and capture every exception and decision in a form that the next implementation can learn from.
The technology to do this exists. The proof points are documented. The category is forming now, and the vendors who move first will have compounding execution intelligence that their competitors will not be able to replicate by hiring more consultants or adding more copilots.
Beacon is the AI implementation orchestration platform for enterprise software vendors. It automates the full HRMS implementation lifecycle from requirements through hypercare, with permission-aware execution, agentic data migration, and configuration-specific UAT generation, without requiring API access or backend integration. Proof of concept in 7 days on your product.








